How I Accidentally Created a Better RAG-Adjacent tool
Ragish a lightweight Alternative to RAG That Outperforms Expectations!
**Ragish **a lightweight Alternative to RAG That Outperforms Expectations!
A RAG (Retrieval-Augmented Generation) tool basically lets one convert a large amount of unstructured data into something query able and retrieve information from it via Natural language.
I for one didn’t even know what a RAG is and got to know what it was after I had built the whole thing!. I work as an intern in an early AI based startup (i.e. every startup in 2024) and was handed over the Enron email dataset which is just a fun little 1.5 GB worth of emails to create something that makes working with emails easier. For the first prototype we had decided to make an interface to essentially “talk” with your emails.
The simplest solutions are often the best. — occam’s razor
This is an anecdote of a rare occasion where I didn’t overthink the technical complexity and just focused on solving the problem. In fact I wouldn’t even have discovered this method if i had known what a RAG is and would have immediately jumped on to the AI train like I usually do.
The thing is all I know is SQL, a bit of AI/ML and a lot of Python which surprisingly was all i needed to make ragish!
RAG Typical Flow:
-
Retrieve relevant documents
-
Augment query with retrieved context
-
Generate response using LLM
The Ragish Flow:
 General flow of Ragish
General flow of Ragish
-
Extract immediately available relevant data and add it all into A database of your choice.( I had the best results with SQL)
-
Select the key data field from your data which for me was the body of the emails , and Extract named entities and provide a category to this field using a model of your choice and add this to your database too.
-
Train an LLM to generate SQL queries from natural language for this DB’s Schema and Make sure to give examples on how to make use of the NER data and Categories!.
-
retrieve the data from the SQL query and Generate a response using LLM.
But how would this be better than a typical RAG you ask?, Well in 2 ways
-
On Vectorizing the data you typically end up with a large DB with the vector embedding where in each of those embedding have 3–6 KB’s of data eventually adding up to Gigabytes just for embedding.
-
As for the augmentation part in a RAG
-
Higher computational cost
-
More prone to hallucination
-
Less predictable results
Ragish solves these issues by,
-
The NER and text categorizer just adds a few more bytes of data as they are essentially just a tiny JSON and a text phrase.
-
Generating the SQL query from LLM,
-
Much lower computational cost due to reduced token consumption
-
More deterministic and precise
-
And its obviously much faster … its SQL!
This method works best if you have a large amount of small chunks of data or something that can be divided into small chunks which is why it worked so well with the email dataset. It could also work on legal docs , religious scriptiures , Medical data like International Classification of Diseases etc all these are either already small chunks or can be converted into small chunks while maintaining their uniqueness.
The con of this method is that this method fails to work as the size of individual data points reaches a size where NER and the text categories just wouldn’t be enough to accurately determine the underlying data.
Lets get nerdy and look at some bad code on how I implemented this and how well it works
Retrieval
First I made use of Regex to parse the emails dataset to get the headers like names, emails, sender , receiver etc. to add it to a class object.
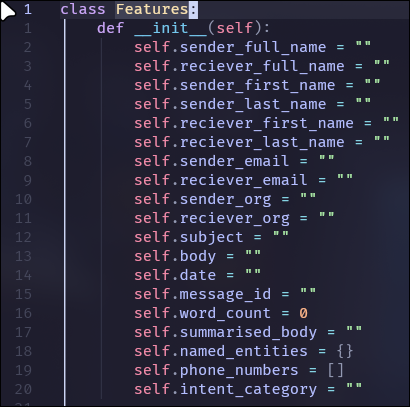 data class schematics
data class schematics
To get the Named entities I used Spacy’s NER that comes with the en_core_web_sm model
# Take in the Half filled data object
def process_features(obj_list):
nlp = spacy.load('en_core_web_sm')
i=0
for objs in obj_list:
#NLP object of the body
doc = nlp(objs.body)
#get the word count
objs.word_count=sum(1 for token in doc if token.text.isalnum())
# add all the Named entities to a Dictionary
named_entity_lists={}
for ent in doc.ents:
if ent.label_ not in named_entity_lists:
ent_list = []
ent_list.append(str(ent))
named_entity_lists[ent.label_] = ent_list
else:
named_entity_lists[ent.label_].append(str(ent))
objs.named_entities = named_entity_lists
print(i)
i+=1
If you are wondering what are all the possible named entities available , here you go !
Lastly in the Retrieval Phase, **classy classification** library!
 All the data needed for categorization
All the data needed for categorization
What classy does is quite impressive, with just 3 examples for each category you can get really good results with classy. I had used 12 categories for my data which was sufficient
Note: To my knowledge its always **better **to have a larger number of categories when using a categorizer like classy , experiment with the **quality **and quantity of categories to get the best results!
Configuration and Code for classy
nlp = spacy.blank("en")
nlp.add_pipe(
"classy_classification",
config={
"data": data,
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
"device": "gpu",
},
)
def categorize_mail(obj):
doc = nlp(obj.body)
cats = doc._.cats
predicted_category = max(cats, key=cats.get)
print(f"{predicted_category}")
return predicted_category
Great now we got the Object is ready with all the context needed, I used **psycopg2 **and pushed it to postgreSQL
Augmentation
Imagine you’re looking for a specific email about a meeting with Allen. In a traditional RAG system, you’d have:
-
Vague search across massive embeddings
-
Potentially irrelevant results
-
High computational cost
In Ragish’s augmentation, you have:
- Precise Categorization
-
Email is pre-labeled as “meeting schedule”
-
Named entity “Allen” already extracted
- SQL Query Generation
-
Directly targets “meeting” category
-
Filters for “Allen”
-
Exact, fast retrieval
We used Mistral’s Codestral Model to generate the SQL queries.
I've created a gist if you are interested on how i built the bot .The gist of the gist is :-
-
Specifically train the bot to use the named entities and categories
-
Go all in while making the system prompt as input tokens are cheap
-
Do make use of the ***Guidelines for Query Generation ***part of the gist as it has some good techniques to get better data.
Generation
The generation part is pretty straight forward and pretty much exactly the same as a typical RAG so here is a working example of Ragish step my step
 Claude LLm
Claude LLm
when this text is passed to the SQL query bot :
 SQL query from LLM’s prompt
SQL query from LLM’s prompt
The 10 email bodies and the rest of the columns SQL returned, I simply copy pasted into claude and this was the responce.
 final response
final response
Oncourse I still haven't hooked it all up into one nice app but that's for later The proof that this works is clear as day!
The point I wanted to make was you don’t need a 1000 dimension vector to categorise your data then work with a vector DB to retrieve the relevant data , instead if you know your data well you can vectorize it yourself into a smaller number of dimensions which you name and create yourself . Ofcourse vectorizing has its own advantages like better semantic mapping but you could still go a long way without doing it the traditional way
Its still a work in progress. I will definitely update on the Statistics of this method
The Road Ahead for Ragish
As an intern stumbling through an AI startup, I accidentally created something kinda cool. This wasn’t some master plan — just me trying to solve a problem with the tools I knew.
“Necessity is the mother of invention” — Plato
Ragish is proof that you don’t need a PhD or cutting-edge infrastructure to build something innovative. Sometimes, all you need is SQL, some Python, and the audacity to try something different.
Next steps involve expanding its versatility — from corporate communications to medical records, legal documents, and beyond.
Want to Join the Chaos?
Let’s build an open-source library that makes this whole process easier.
No bullshit, just code! 🐍🤖
Interested? Hit me up! on twitter/X