Mem-Brain: Your Organization's Institutional Memory
Published on 1/27/2026
It's 2026, and everyone is building a memory solution for AI agents. Vector databases, RAG frameworks, conversation history managers, knowledge graphs, and they're everywhere. If you're feeling fatigue from yet another memory tool promising to solve context windows, you're not alone.
But here's what history teaches us. When industry fragmentation happens - racing to solve the same problem in a hundred different ways- it signals a more profound architectural shift. The problem isn't that memory is hard. The problem is that we're trying to build permanent systems with temporary tools.
We saw similar patterns with databases fifteen years ago. MongoDB won the "easy and flexible" crown, but PostgreSQL won the enterprise crown because relationships matter. You could hack relations in document stores, but eventually every serious application needed real joins, real constraints, and absolute integrity.
Standard RAG is today's MongoDB. It's the default because it's simple: chunk documents, embed them, retrieve top-K, stuff into context. It works for demos. It fails for production. RAG treats memory like a search index, whereas indexes should be treated as living systems.
Mem-Brain is the PostgreSQL moment for AI memory.
The Architecture: Why Search Is Not Enough
Traditional enterprise search finds documents. Mem-Brain finds meaning.

We built this on a unified graph architecture where every piece of organizational knowledge (customer preferences, project decisions, compliance notes, competitive intel) becomes an atomic note. Storage is the easy part. The real value is in how we handle relationships.
Edges That Think: The Secret of Unified Graph Search
Most systems store relationships as metadata tags, but Mem-Brain embeds them as searchable intelligence, showcasing its advanced relationship handling that sets it apart.
Every link between memories is stored as two to three natural-language questions, each with its own vector embedding. When you search, the system queries both memory nodes and relationship edges in a single pass. If your query semantically matches a link better than a node, you get back the relationship (with its question-based description), complete hydration of source and target nodes, and orbit-one neighbors of both nodes (their immediate connections).
The traversal of memories and relationships is multi-hop reasoning within a single search operation. No recursive queries. No RAG prompt gymnastics.
The hybrid scoring formula balances semantic relevance with usage patterns: 80% cosine similarity of embeddings plus 20% logarithmic importance boost based on retrieval frequency. Frequently accessed memories (Super Hubs) get a PageRank-style boost, so the system learns what actually matters to your organization.
The Guardian: Intelligent Graph Curation

New information undergoes a Guardian process that uses structured LLM reasoning to verify and refine connections, ensuring the graph remains accurate and relevant.
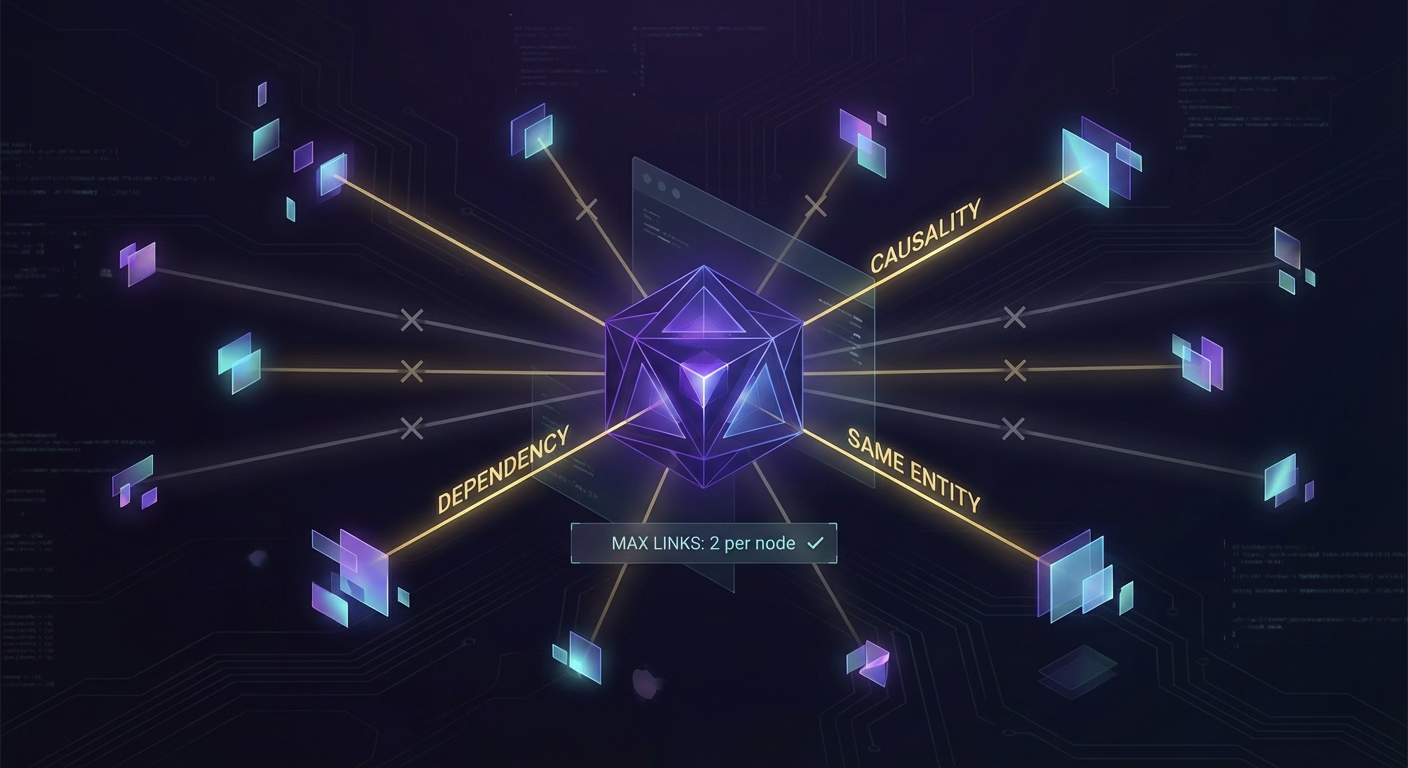
Linking Logic (capped at two links per memory to prevent hairball graphs):
- Causality: "lactose intolerant" leads to "avoids dairy."
- Same Entity: "works at AlphaNimble" connects with "AlphaNimble is a start-up."
- Dependency: "bought bike" relates to "bought bike basket."
- Continuation: "learning guitar" flows to "struggling with F chord."
- Topic deepening: "uses Python" expands to "Pandas library tips."
What it rejects: generic keyword overlap, coincidental mentions, weak semantic matches.
The Guardian casts a wide net (k=10 semantic neighbors) to prevent Candidate Starvation, where high-degree hubs crowd out relevant but less connected memories. It uses pure cosine similarity during linking to ensure new information connects to the proper context, not just the popular one.
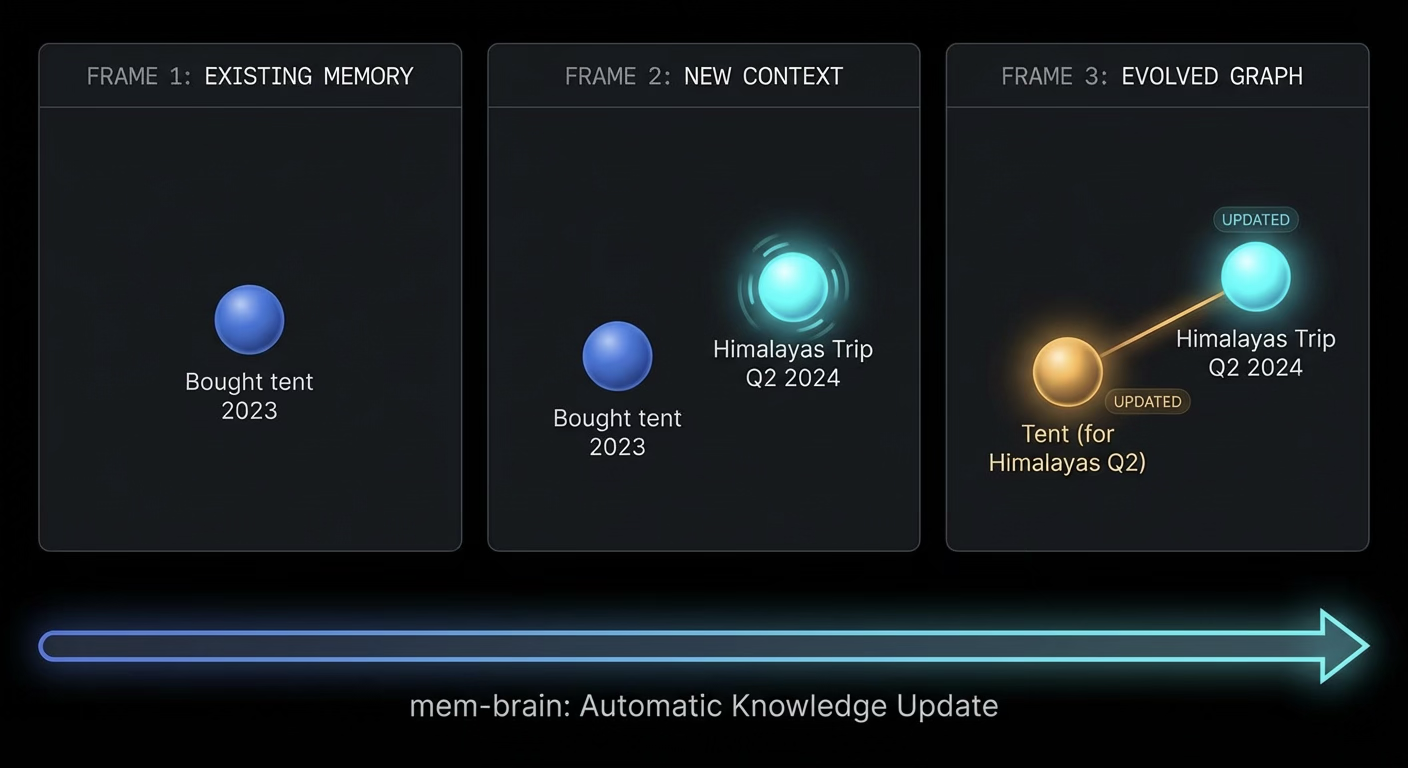
Recursive Neighborhood Enrichment: Memory That Updates Itself
Evolution does not just link memories. It updates them automatically, providing your organization with a reliable, up-to-date knowledge base.
When a new memory arrives, the Guardian can update tags of neighboring memories to reflect new context, rewrite context descriptions of old memories based on discoveries, or break stale links (for example, when someone is no longer vegetarian, unlink previous diet recommendations).
Example: You add "Planning a trip to the Himalayas in Q2." The system finds an old memory: "Bought a tent last year." It does not just link them. It updates the tent memory's context to: "Tent purchased for the Himalayas expedition, Q2." Now, when your team searches for "Himalayas," the tent surfaces immediately, even though the original memory never mentioned it.
The update happens asynchronously in the background after every addition. Users never wait for evolution. It runs as an asynchronous background task while the system returns the memory ID instantly.
Technical Foundation Built for Scale
- Local Embeddings: We use FastEmbed with nomic-ai/nomic-embed-text-v1.5-Q, a quantized local embedding model that runs in 100-200MB RAM. The model ensures zero latency on embedding calls, zero cost at scale, data privacy, and deterministic results.
- Lazy Hydration: Search does not load full objects until after scoring. The system scores all memories and links using pure vector math, then only hydrates the top K results (typically 5-10). Scoring is O(n) in pure NumPy; hydration is O(k).
- PostgreSQL + pgvector: You are not betting on a proprietary vector database. We use standard PostgreSQL with the pgvector extension as our foundation. So you can efficiently run it locally too.
From Silos to Stories: How It Works in Practice
Traditional enterprise search finds documents. Mem-Brain finds meaning.
Example:
- Memory A says, "Enterprise client Acme Corp has a zero-tolerance policy for downtime during fiscal year-end."
- Memory B says, "Proposed infrastructure migration for Acme Corp scheduled for Q4."
The Link is stored as literal questions: "Does this migration timeline conflict with Acme Corp's blackout periods?", "What are the risk factors for FY-end-sensitive clients?", etc.
When your account manager asks, "Is this migration plan safe?" they do not need to know what to search for. The question finds its own answer: "This conflicts with Acme's FY-end policy. Recommend rescheduling," as the question string itself has a high semantic similarity with the link description we stored!
Total query time: under 100ms.
Vibe-Traversal: Following the Narrative Thread
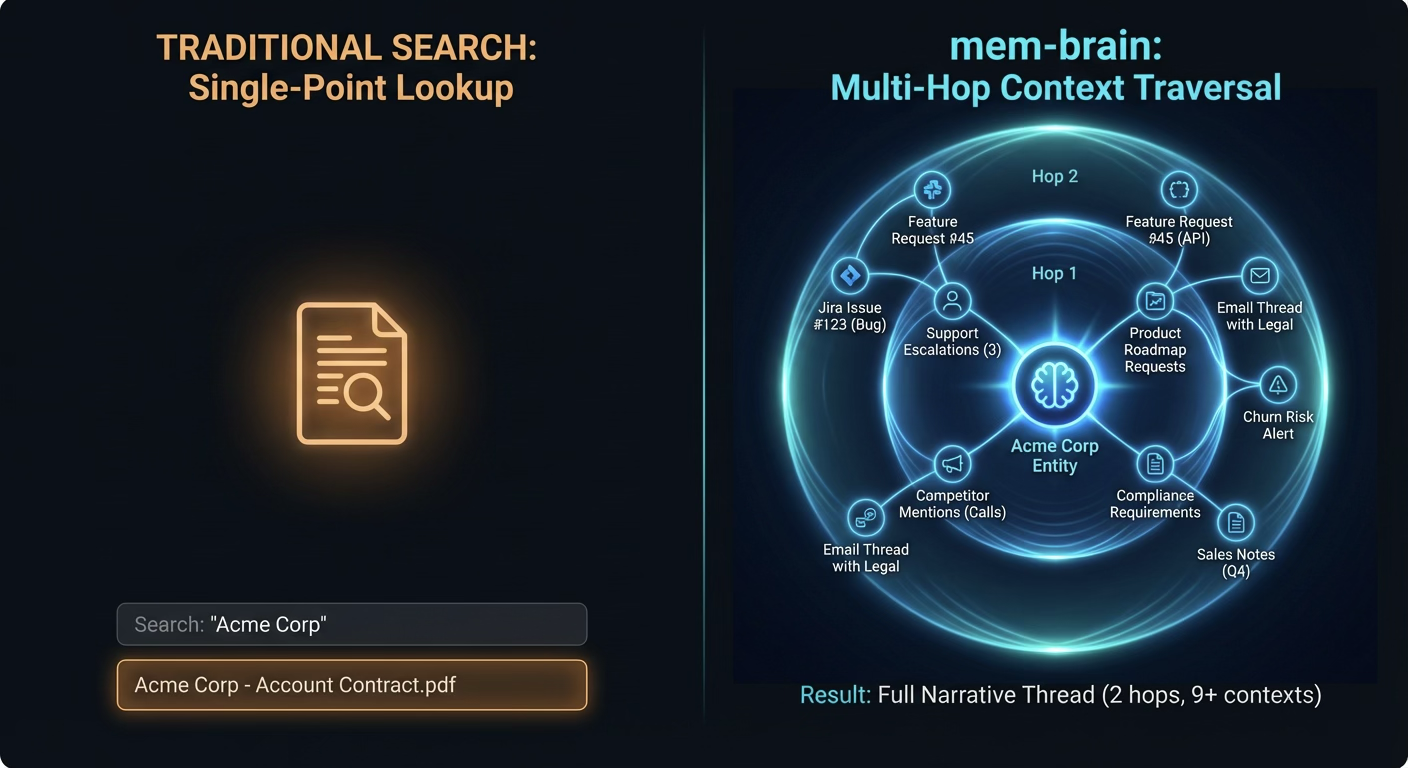
Single-point lookups give you facts. Traversal gives you implications.
Our get_neighborhood(memory_id, hops=2) and find_path(from_id, to_id), along with our robust search tools, let agents (human or AI) explore the context graph with configurable depth.
Real-world use case: When your sales team searches for "Acme Corp," Mem-Brain surfaces:
- The last three support escalations (Customer Health context)
- Product roadmap items they have requested (Feature Gaps context)
- Competitor mentions in recent calls (Churn Risk context)
- Compliance requirements from their contract (Legal Constraints context)
Neighborhood expansion uses breadth-first search with a configurable hop limit (1-5). At hop=2 with a branching factor of ~3, you get 9 related memories. At hop=3, you get 27. The expansion is how narrative context compounds.
Evolution: Agent-Managed Knowledge That Stays Current
Organizational memory decays. Mem-Brain gives your AI agents the tools to refresh their own memories.
The process is not a black-box automation that secretly rewrites your knowledge graph. It is an agentic control layer that puts decisions in the hands of the AI agents you deploy.
The Intelligence Loop works like this:
- Search-then-Store (Agent-Initiated): Before adding information, your agent checks for existing context. When similar memories are found, the agent merges or updates instead of creating duplicates. The agent decides and manages its own memories using its own strategies based on its learning, not the system's.
- PageRank-Inspired Scoring (Automatic): This is the only component that runs without agent direction. Retrieval count gets a logarithmic boost, so frequently accessed memories naturally surface faster. Core organizational knowledge becomes easier to find over time.
- Recursive Context Refinement: When an agent adds a memory, it can choose to enrich neighboring memories. It can update their tags, rewrite their context, or break stale links. The agent sees the complete graph and decides what needs refreshing.
- Agent-Led Pruning: Your agents use the
unlink_memoriestool to sever outdated relationships. When a project ends, a vendor relationship dissolves, or a policy changes, the agent prunes the narrative to keep the graph honest and up to date.
The architecture is built for agentic comfort. Your AI agents do not just read from the graph; they manage it. They become stewards of your organizational memory, keeping it accurate, relevant, and free of rot.
Comprehension: The Last Mile of ROI
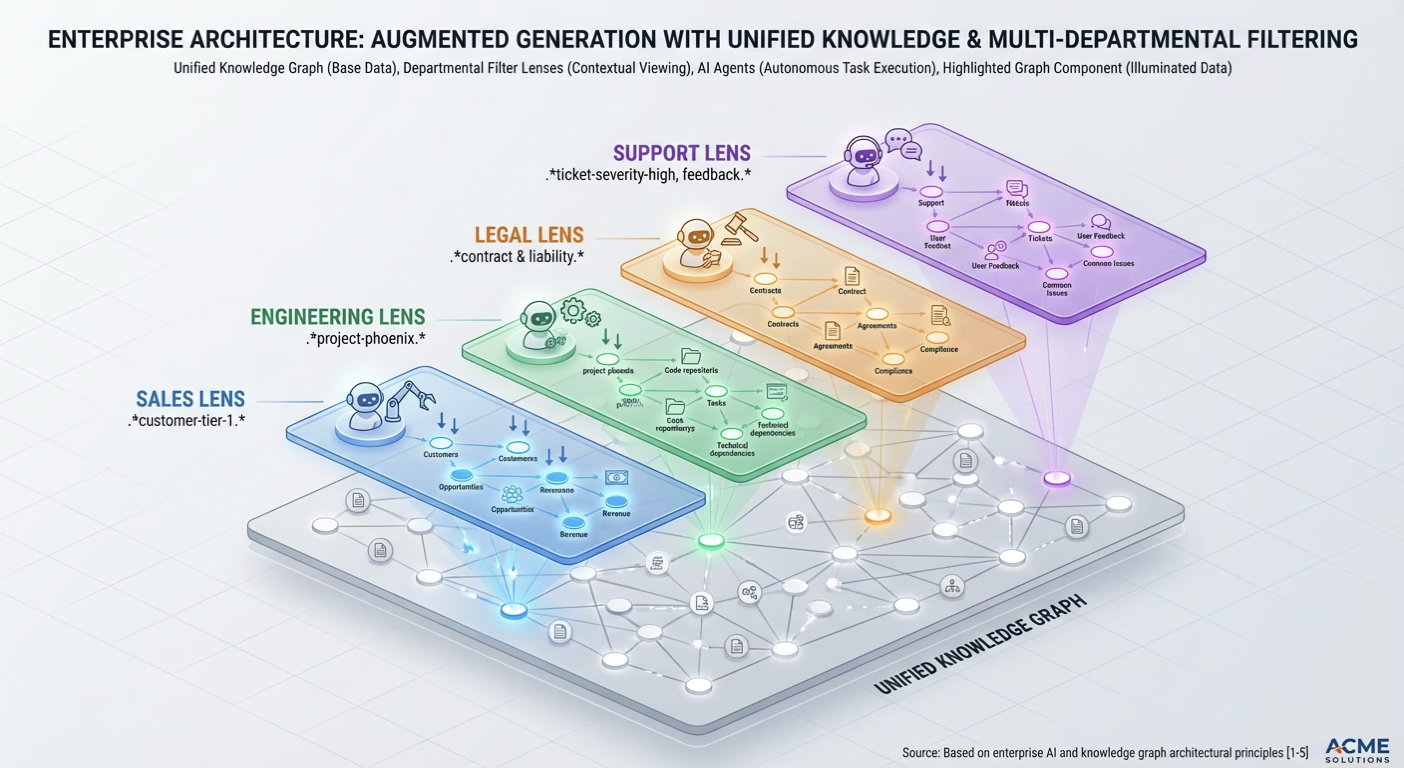
Here is where data becomes decisions. Because Mem-Brain stores relationships as semantic questions, it synthesizes across domains.
Domain Isolation plus Global Context: Our keyword_filter (regex-based) allows different functions to operate on the same graph with function-specific lenses:
keyword_filter="project-phoenix"(Engineering)keyword_filter="customer-tier-1"(Support)keyword_filter="compliance-.*-2024"(Legal)
The outcome is contextual multi-tenancy: global organizational memory with local team focus.
Use Cases: Where Mem-Brain Wins
- Customer Success and Retention: Unify support tickets, sales notes, and product usage to see the full account risk story.
- Compliance and Risk Management: Automatically link regulatory requirements to operational processes.
- AI Governance: Where explainability, traceability, and transparency are paramount.
- Engineering and Product Intelligence: Connect user feedback to technical debt and roadmap priorities.
- M&A and Due Diligence: Rapidly build a knowledge graph of target companies to spot risks or opportunities.
- Multi-Agent AI Orchestration: Deploy specialized AI agents that all draw from and contribute to the same evolving knowledge graph.
Built for Enterprise Reality
Mem-Brain integrates with your existing stack without a rip-and-replace. It is API-first, with MCP (Model Context Protocol) integration that works natively with Cursor, Claude Code, OpenCode, and any agentic systems that support MCP.
At Alpha Nimble, we are not building a better database. We are building the missing cognitive infrastructure that turns your organization's collective experience into a competitive advantage.
Alpha Nimble — Transforming enterprise knowledge into organizational intelligence.
See Mem-Brain in Action
Explore live technical documentation, integration patterns, and sandbox environments at: https://www.alphanimble.com/projects/mem-brain-demo/docs
The demo includes:
- API reference (REST + MCP protocol)
- Integration guides (Python, TypeScript, cURL)
- Interactive graph explorer (Visualize knowledge connections)
- Deployment templates (Docker, Kubernetes, AWS ECS)
No sales pitch. Just working on software.